
유진의 코딩스토리
Python ML 실습 [와인 분류 - 분류 모델] 본문
https://archive.ics.uci.edu/dataset/186/wine+quality
UCI Machine Learning Repository
This dataset is licensed under a Creative Commons Attribution 4.0 International (CC BY 4.0) license. This allows for the sharing and adaptation of the datasets for any purpose, provided that the appropriate credit is given.
archive.ics.uci.edu
와인 데이터셋은 매우 유명해서 다 알 것이다.
해당 와인 데이터셋에서 숫자 데이터인 alcohol, sugar, pH 컬럼만 가져와 레드와인인지 화이트 와인인지 분류하는 모델을 만들어보자.
이번 실습에서는 다양한 분류 알고리즘을 알아보는게 주 목적이므로 전처리를 최소화하는 방향으로 실습할 예정이다.

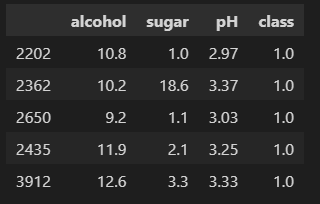
class값이 1인 경우 화이트와인, 0인 경우 레드와인으로 분류된다.
데이터 탐색
info()

행은 6497개, 열은 4개로 구성되어 있으며 모든 컬럼이 float형태로 되어있다.
예측하고자 하는 target변수는 class변수이며 모든 컬럼에서 결측값이 없으므로 따로 결측값을 처리해줄 필요는 없다.
describe()

suger의 경우만 다른 컬럼에 비해 값의 범위가 넓은 것을 확인할 수 있다. 이러한 경우 가중치 불균형 문제를 야기할 수 있는데 범위가 큰 특성은 작은 특성에 비해 상대적으로 더 큰 가중치를 부여받기 쉬워서 모델이 해당 특성에 더 민감하게 반응할 수 있다.즉, 특정 feature가 과도하게 중요한 것으로 인식된다.
그렇기 때문에 정규화나 표준화 작업이 필요하다.

독립변수인 x 데이터와 분류하고자하는 y값을 나눈다.
표준화

독변변수(X)들을 평균이 0 이고 표준편차가 1인 표준정규분포를 따르도록 표준화를 시켜준다.
데이터셋 분할

학습데이터를 80%, 테스트 데이터를 20%로 분할하였다.
Logistic Regression
Logistic Regression은 종속 변수가 각 클래스에 속할 확률을 예측하며 해당 예측 결과를 기반으로 분류를 수행합니다.

학습데이터의 정확도는 0.78, 테스트데이터의 정확도는 0.77로 학습데이터의 결과가 나왔다.
하지만 아직 비교 대상이 없으므로 좋은 성능인지 판단하기 어렵다.
그 외의 분류모델을 학습해보고 결과를 비교해보자.

coef_ : 회귀계수를 출력. 출력 순서대로 각 독립변수의 회귀계수이다. (alcohol, sugar, pH 순)
intercept_ : 회귀 절편 값 출력
회귀계수는 각 feature의 중요도를 나타내는데 이 절대값이 클수록 해당 feature가 예측에 중요한 영향을 미친다는 것을 의미한다. 특히 로지스틱 회귀모델에서 회귀계수가 양수인 경우 긍정(1)로 분류될 확률이 높고 음수일 경우 부정(0)으로 분류될 확률이 높다는 것을 의미한다.
이를 해석해보면 acohol이 높을 수록, 당도가 높을 수록, pH산성도가 낮을수록 화이트와인으로 분류될 확률이 높다는 것을뜻한다. 또한, suger의 회귀계수의 절대값이 1.65로 가장 크기 때문에 당도가 화이트와인과 레드와인을 분류하는데 가장 중요한 역할을 하고 있다는 것으로 해석할 수 있다.
DecisionTree classification
규칙에 따라 데이터를 분할하여 트리 구조로 데이터를 분류, 예측하는 모델

의사결정트리는 데이터를 분할 시 어떤 기준을 가지고 분류, 예측할까?
불순도 : 분류하려는 데이터 집합에서 서로 다른 클래스(범주)가 섞여 있는 정도를 나타내는 지표로 불순도가 낮아지는 방향으로 학습을 진행한다.
데이터 분리 기준
▶ Gini 계수 : 불순도를 측정하는 지표. 노드의 불순도를 측정하여 데이터 분할
▶ Entropy : 불순도를 측정하는 지표. 정보량의 기댓값으로 엔트로피가 감소할수록 정보 이득을 얻었다고 볼 수 있다.
장점 : 데이터 전처리의 필요성이 낮다. 결측치처리나 스케일링 없이도 사용 가능하다.
단점 : 트리의 depth가 너무 깊으면 과적합의 위험이 있다.

우선 결정트리의 경우 스케일링이 필요하지 않기 때문에 스케일링 하지 않은 원본 데이터로 데이터셋을 분할해줬다.

그 후 모델을 학습하고 모델의 정확도를 확인해보면 학습데이터는 0.99, 테스트 데이터는 0.85로 학습데이터가 과하게 학습된 과대적합된 것을 알 수 있다.
학습데이터에 너무 fit하게 학습된 모델을 테스트 데이터에 적용할 경우 학습데이터에 비해 더 떨어지는 성능 결과를 얻을 수 있다.
이는 depth가 너무 깊어 과적합이 되었을 확률이 높은데 이를 확인하기 위해 결정트리를 시각화해보자.
결정트리 시각화


sklearn의 tree모듈에서 plot_tree를 사용해 결정트리의 트리구조를 시각화 해보았다.
시각화 결과 depth가 매우 깊어 과적합이 된 것을 확인할 수 있다.


filled=True 옵션을 지정할 경우 각 노드의 색을 채워주는 역할을 한다.
각 노드의 색상은 해당 노드의 순도(purity) 또는 예측 클래스의 확률에 따라 달라진다. 예를 들어, 노드에 속한 데이터가 한 클래스에 완전히 속하는 경우(불순도가 낮은 경우) 색상이 진하게 나타나고, 여러 클래스가 섞여 있는 경우(불순도가 높을 경우) 색상이 더 옅어지거나 혼합된 색으로 표현됩니다.
위 루트노드부터 살펴보면 sugar < = 4.325 라는 조건을 기준으로 True일 경우 왼쪽 노드로 아닐 경우 오른쪽 노드로 데이터가 분류되고 5197개의 샘플을 기준으로 왼쪽노드에는 2992개의 샘플이, 오른쪽 노드에는2275개의 데이터 샘플이 분류 된 것을 알 수 있다. 또한, 왼쪽 노드의 경우처럼 gini계수(불순도)가 낮을 수록 연한 색을 띄는 것이 특징이다.
다시 왼쪽 노드에서 sugar <= 1.625라는 조건을 기준으로 True일 경우 왼쪽노드로 아닌 경우 오른쪽 노드로 분류된다. 그리고 가장 마지막 노드인 리프노드 중 붉은 색을 띄는 노드가 보이는데 이는 레드와인(0)으로 분류한 경우를 의미한다.
가지치기
결정트리의 과적합을 방지하는 방법 중 하나로 가지치기가 있다.
가치치기로 트리의 깊이를 제한하여 과적합을 방지하는 역할을 한다.
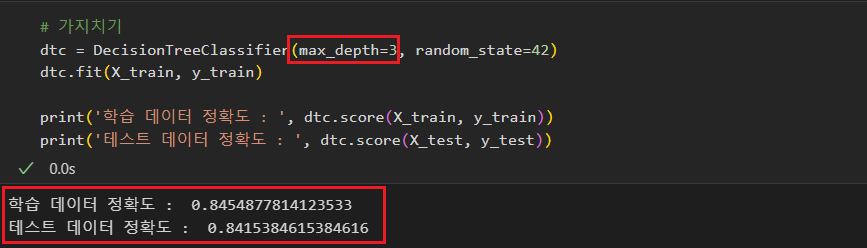
max_depth를 3으로 제한하여 학습을 진행하였더니 정확도는 살짝 떨어졌지만 학습데이터와 테스트데이터의 정확도가 비슷한 수준으로 나온 것을 보아 학습데이터를 과하게 학습하는 경향이 줄어든 것을 알 수 있다.
GridSearchCV
이제는 결정트리의 매개변수 값을 바꿔가며 가장 성능이 좋은 최적의 모델을 찾아보도록 하자.
매개변수의 값을 매번 바꿔가면서 조정하기는 어려운 일이다. 그러므로 여러 하이퍼파라미터 조합을 탐색하는 GridsearchCV 모듈을 사용하면 쉽게 최적의 매개변수를 찾을 수 있다.

GridSearchCV의 옵션 params를 통해 하이퍼파라미터를 딕셔너리 형태로 지정해준다.
- min_impurity_decrease : 노드를 분할할 때 필요한 최소 불순도 감소량.
- max_depth : 최대 깊이.
- min_samples_split : 노드를 분할하기 위해 필요한 최소 샘플 수. 더 세부적으로 데이터를 분할하는 것을 방지
min_impurity_decrease는 0.0001 부터 0.001까지 0.0001간격으로 9번 진행하고 max_depth는 5부터 20까지 1간격으로 15번 진행하고 min_samples_split는 2부터 100까지 10간격으로 10번 진행하므로 총 1350번의 학습을 진행한다.
결과

best_params_를 통해 최적의 매개변수 조합을 확인할 수 있다.

best_estimator_를 통해 최적의 매개변수의 조합으로 된 모델을 통해 학습데이터와 테스트데이터의 정확도를 구해보았다.
가장 성능이 좋으면서도 학습데이터의 정확도와 테스트데이터의 정확도가 큰 차이가 나지 않은 것으로 보아 과적합이 발생하지 않은 결과가 나왔음을 알 수 있다.
RandomSearch
GridSearchCV를 사용할 때 스스로 하이퍼파라미터 조합을 어떻게 지정할 지 어려울 때가 있다.
그런 경우 사용하는 것이 RandomSearch인데 이는 하이퍼파라미터의 일부 조합을 랜덤하게 선택하여 탐색한다.

randint를 이용해서 하이퍼파라미터값들을 난수로 생성하여 해당 하이퍼파라미터 중 일부 조합만 무작위로 선택하여 탐색한다. 이때 n_iter=n 옵션을 통해 랜덤하게 선택할 조합의 수를 지정해주어 계산비용과 시간을 조절할 수 있다는 장점이 있다. 하지만 최적의 하이퍼파라미터를 놓칠수도 있으므로 GridSearchCV에 비해 예측력이 떨어질 수 있다는 단점이 있다.
추가로 n_job=-1 옵션은 모든 CPU 코어를 사용해 병렬 처리를 수행한다는 의미이다.
결과

최적의 하이퍼파라미터 조합을 확인해보았을 때 GridSearchCV의 결과에서는 max_depth=14였던 것에 비해 maz_depth=39로 트리의 깊이가 더 깊어진 것을 확인 할 수 있다.

학습데이터와 테스트데이터의 정확도는 0.89, 0.86으로 GridSearchCV와 비슷한 정확도가 나타난 것을 볼 수 있다.
'Azure 실습 > Azure machine learning' 카테고리의 다른 글
| Python ML 실습 [자전거 대여 수요 예측 - 회귀 모델] (0) | 2024.10.16 |
|---|---|
| Azure ML Designer 실습 [군집 모델] (0) | 2024.10.11 |
| Azure ML Designer 실습 2 [자전거 대여 수요 예측 - 회귀 모델] (0) | 2024.10.10 |
| Azure ML Designer 실습 [로켓 발사 여부 예측 - 분류 모델] (0) | 2024.10.08 |



