
유진의 코딩스토리
Azure ML Designer 실습 2 [자전거 대여 수요 예측 - 회귀 모델] 본문
Azure ML Designer 실습 2 [자전거 대여 수요 예측 - 회귀 모델]
놀고먹는 유진 2024. 10. 10. 10:57
문제정의
[자전거 수요에 영향을 미치는 요소]
- 날씨
- 계절
- 휴일/평일
◆ 주제 : 날씨, 계절, 휴일/평일 여부에 따른 자전거 수요 예측 모델 구현
데이터 확인

우선 엑셀파일에서 데이터를 대충 확인해보자.
• day – 관찰이 이루이진 날짜
• mnth – 관찰이 이루어진 월
• year – 관찰이 이루어진 년도
• season – 계절 (1: 겨울. 2: 봄, 3: 여름, 4: 가을)
• holiday – 공휴일 여부 (1:공휴일, 0: 공휴일아님)
• weekday – 요일 (0:일, 1:월, 2:화, 3:수, …, 6:토)
• workinday – 근무일 여부 (1:근무일, 0:근무일 아님)
• weathersit – 날씨 상황
• 1 : Clear, Few clouds, Partly cloudy, Partly cloudy
• 2 : Mist+Cloudy, Mist+Broken clouds, Mist+Few clouds, Mist
• 3 : Light Snow, Light Rain+Thunderstorm+Scattered clouds, Light Rain+Scattered clouds
• 4 : Heavy Rain+Ice Pallets+Thunderstorm+Mist, Snow+Fog
• temp, atemp – 온도와 체감 온도
• hum - 습도
• windspeed – 바람의 세기
• rentals – 자전거 대여수 – 라벨(target)
모델링 유형 - 회귀

머신러닝은 3가지 기법으로 나뉘어짐.
이번에 진행할 모델의 기법은 정답이 주어져 있으며 자전거 수요량(rentals)가 수치형으로 되어있어 회귀모델을 사용하여 머신러닝을 진행할 예정이다.
특히, 독립변수가 여러개이므로 다중회귀에 해당함.
머신러닝 리소스는 이미 만들어진 리소스 그대로 사용 예정.
머신러닝 studio

Azure 서비스에서 머신러닝 작업을 수행하기 위한 웹 포털.
머신러닝을 진행하기 전 로컬 파일에 있는 데이터셋을 클라우드 환경으로 업로드하고 머신러닝에 필요한 컴퓨팅 자원을 사용하기 위해 컴퓨팅 대상을 정의해야 함.
데이터셋 등록



데이터 이름과 타입을 설정 (데이터를 표 형식으로 설명)
데이터를 어디에서 가져올지를 지정해준다. 자전거 렌탈 데이터는 로컬 드라이브에서 가져올 예정.


Blob(binary large object) storage : 대량의 비정형 데이터 특화 저장소


데이터셋 업로드 완료
Compute Target 설정
저번 분류모델 실습 시 compute instances 설정 완료
해당 compute instances을 그대로 사용할 예정

복잡한 딥러닝 모델이 아닌 간단한 회귀모델이며 데이터셋 크기도 50개 정도로 실습을 위한 매우 작은 데이터셋이므로 cpu로 지정하고 VM크기도 Standard D2_v3 (2vCPU, 8GB RAM)로 지정해줘도 무방하다.
ML Designer
파이프라인 생성

데이터셋 가져오기


의미 없는 데이터를 확인한다.
의미 없는 데이터는 추후에 컬럼 삭제할 예정.
year의 경우 모두 2011년이므로 의미 없다고 여겨 삭제할 컬럼으로 염두.
mnth, day의 경우 모두 holiday, weekday, workingday로 자전거 수요에 영향을 줄만한 요인으로 구분해두었기 때문에 큰 의미가 없을 것으로 판단.
범주형 데이터와 수치형 데이터인 컬럼을 확인해준다.
▶ 범주형 데이터 : season, holiday, weekday, workingday, weathersit
▶ 수치형 데이터 : temp, atemp, hum, windspeed, rentals


히스토그램, boxplot을 통해 시각화
기초통계량 뿐만 아니라 개수, 누락값, 분산, 왜도, 첨도, 분위수 등을 확인할 수 있다.
Feature 선택


Missing Value 처리

메타데이터 변경
범주형 데이터의 경우 Edit Metadata를 통해 타입이 integer(정수형)로 되어있는 컬럼을 categorical(범주형)로 변환 후 Convert to Indicator Values를 통해 원핫 인코딩
Edit Metadata

Convert to Indicator Values



원핫 인코딩의 경우 예를 들어 1,2,3,4 로 범주화 되어 있는 컬럼의 경우 순서가 반영된다.
1보다는 2가 크고 2보다는 3이 크고..
이러한 순서성을 반영하지 않게하려면 원핫 인코딩을 통해 순서성을 없애준다.
정규화 및 표준화
데이터의 각 수치형 값을 가지는 특성(feature)들이 서로 단위와 분포가 다르므로 이를 모델에 비슷한 영향력을 갖도록 변형하여 통일해줘야함
- 정규화 : 각 특성의 범위 또는 단위가 다른 값들을 비슷한 [0,1]사이의 값으로 변환
- 표준화 : 각 특성의 값을 평균이 0이고 표준편차가 1인 표준정규분포를 이루도록 분포를 변환

수치형 컬럼 (temp, atemp, hum, windspeed)을 지정하여 Zscore 정규를 진행
- Min-Max 정규화 : feature들간의 범위 차이가 매우 클 경우 사용. 이상치(outlier)에 민감.
- Z-score 정규화 (Standardization) : 데이터가 정규분포를 따른다는 가정이 있을 때 가장 효과적. feature들간의 단위가 다를 경우 사용.이상치(outlier)에 덜 민감하다는 장점이 있음.
수치형 컬럼(temp,atemp,hum,windspeed)를 zscore로 변환하여 표준화 해준다.

작업 > 데이터 미리보기를 통해 표준화 진행 결과를 확인

각 수치형 데이터가 표준정규분포로 변환된 것을 확인
데이터 분리

▶ Split Rows : 행 단위로 분리
▶ Fraction of rows in the first output dataset : 첫번째 데이터셋(train data)의 비율을 0.7로 설정
▶ Randomized split : 데이터를 무작위 섞어 split
▶ Radom seed : True로 시드 고정 (False일 경우 실행할 때마다 데이터 분할 결과가 달라짐)
▶ Stratified split : 층화 샘플링 옵션으로 데이터 분할 시 특정 범주의 분포를 동일하게 유지(특정 범주로 편향된 데이터 불균형이 있을 경우 사용, 회)
[Stratified split의 주요 기능]
▶ 데이터 불균형 :
▶ 회귀 모델 사용 : 회귀 작업의 경우 target값의 데이터의 분포를 기준으로 데이터를 층화시켜 분할
우선은 stratified split을 False로 하고 진행.
모델링
모델 하이퍼파라미터 선택

Machine Learning Algorithms > Regression 항목을 보면 다양한 회귀모델 컴포넌트를 제공함.
Learn more을 누르면 아래와 같은 해당 모델에 대한 자세한 설명을 볼 수 있다.

Decision Tree Regression모델과 다르게 Boosted Decision Tree Regression 모델은 각 tree가 이전 tree에 의존적(순차적)이 정확도가 개선되었으며 LightGBM기반의 모델임을 알 수 있다.
더 나은 성능의 모델을 채택하기 위해 3가지 모델을 학습시킬 예정이다.
첫번째로는 Linear Regression(선형회귀) 모델, 두번째는 나무의 개수를 여러개로 조정한 Decision Forest Regression(랜덤 포레스트), 세번째는 Boosted Decision Tree Regression

▶ Solution method : Online Gradient Descent로
▶ Create trainer mode : SignleParameter는 하이퍼 파라미터를 직접 하나씩 설정, ParameterRange는 여러가지 하이퍼 ▶ 파라미터를 조합하여 모델을 학습(여러 하이퍼파라미터 중 최고의 성능을 보여주는 하이퍼파라미터 조합 채택)
▶ Learning rate (학습률) : 경사하강법의 학습률
▶ Number of training epoch (에포크 수) : 전체 데이터 학습 횟수
▶ L2 regularization weight (L2 규제 양) : L2 regularization의 람다(하이퍼파라미터) 지정
▶ Normalize feature : 선형회귀 모델에 사용할 컬럼들 정규화
두번째는 나무의 개수를 여러개로 조정한 Decision Forest Regression(랜덤 포레스트)모델이다.

▶ Create trainer mode : 여러가지 하이퍼파라미터를 조합하여 모델을 학습
▶ Number of decision trees : 결정트리의 수.여러개의 결정트리를 결합한 앙상블 기법인 랜덤포레스트 사용(트리 수가 너무 많을 경우 과적합 위험)
▶ Maximum depth of the decision trees : 결정 트리의 최대 깊이. 트리가 데이터를 분할하는 최대 단계 수
▶ Minimum number of samples per leaf node : 리프노트 당 최소 샘플 수. 트리의 리프 노드에 포함될 수 있는 최소 데이터 수
▶ Resampling method : 리샘플링 방법으로 중복을 허용하는 방법과 중복을 허용하지 않는 방법이 있음. bagging의 경우 중복을 허용하여 무작위로 데이터를 추출하여 모델을 학습한다.
세번째는 boosted dicision tree regression 모델이다.

▶ Create trainer mode : 여러가지 하이퍼파라미터를 조합하여 모델을 학습
▶ Number of decision trees : 결정트리의 수.여러개의 결정트리를 결합한 앙상블 기법인 랜덤포레스트 사용(트리 수가 너무 많을 경우 과적합 위험)
▶ Maximum depth of the decision trees : 결정 트리의 최대 깊이. 트리가 데이터를 분할하는 최대 단계 수
▶ Minimum number of samples per leaf node : 리프노트 당 최소 샘플 수. 트리의 리프 노드에 포함될 수 있는 최소 데이터 수
▶ Learning rate (학습률) : 경사하강법의 학습률. 부스팅 과정에서 각 트리가 이전 트리의 예측 결과에 얼마나 기여할지를 결정. 즉, 가중치를 조정하는 정
▶ Total number of trees constructed : 구성할 트리의 총 개수.
모델 학습

모델 테스트 / 평가



평가지표 - 오차
- Mean_Absolute_Error (MAE) : 예측 값과 실제 값 사이의 차이의 절대값을 평균한 값.
- Root_Mean_Squared_Error (RMAE) : 예측 값과 실제 값의 차이의 제곱을 평균낸 후 제곱근을 취한 값
- Relative_Squared_Error (RSE) : MSE(Mean Squared Error)를 실제값과 평균값의 차이의 제곱평균으로 나눈 값
- Relative_Absolute_Error (RAE) : MAE를 실제값과 평균값의 절대차의 평균으로 나눈 값
- Coefficient_of_Determination (결정계수) : 종속변수의 변동량 중에서 회귀모델로 설명가능한 부분의 비율 즉, 독립변수가 종속변수를 설명하는 정도를 표현하는 지표
MAE, RMAE, RSE, RAE는 0에 가까울수록 예측값과 실제값이 비슷하다는 의미에서 모델이 잘 학습된 것으로 파악할 수 있고 oefficient_of_Determination는 회귀모델로 설명가능한 부분의 비율이므로 0 ~ 1사이의 값이며 0에 가까울수록 모델의 설명력이 나쁘고 1에 가까울수록 모델의 설명력이 좋다는 의미이다. 즉, 1에 가까울수록 모델의 성능이 좋은 것을 뜻한다.



▶ 세가지 모델 중 Decision Tree Regression 모델이 오차는 가장 적고 모델의 설명력은 가장 좋아 성능이 좋은 모델임을 알 수 있다.
예측 결과 확인
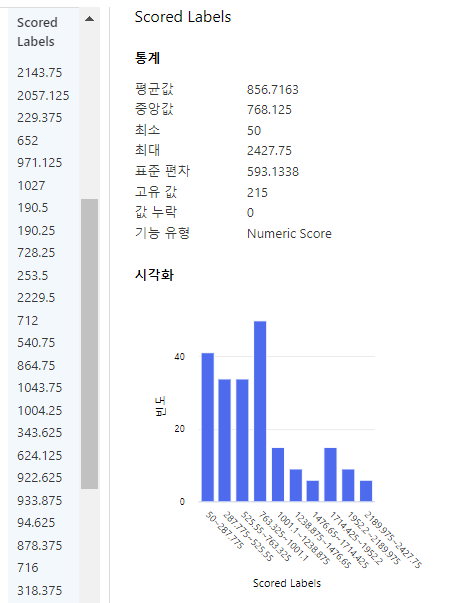
Decision Tree regression 모델을 사용하여 예측한 자전거 수요 예측값을 확인할 수 있다.
또한 score model > 데이터 미리보기 > scored dataset 에서 기초통계량을 확인할 수 있다.
'Azure 실습 > Azure machine learning' 카테고리의 다른 글
| Python ML 실습 [와인 분류 - 분류 모델] (0) | 2024.10.17 |
|---|---|
| Python ML 실습 [자전거 대여 수요 예측 - 회귀 모델] (0) | 2024.10.16 |
| Azure ML Designer 실습 [군집 모델] (0) | 2024.10.11 |
| Azure ML Designer 실습 [로켓 발사 여부 예측 - 분류 모델] (0) | 2024.10.08 |



