
유진의 코딩스토리
Azure ML Designer 실습 [로켓 발사 여부 예측 - 분류 모델] 본문
Azure ML Designer 실습 [로켓 발사 여부 예측 - 분류 모델]
놀고먹는 유진 2024. 10. 8. 14:05
Azure 머신러닝 (Machine Learning)
Azure 클라우드에서 머신러닝을 개발/운영하기 위한 서비스 리소스로 Azure 머신러닝은 Microsoft의 클라우드 서비스를 이용해 머신러닝 모델을 쉽게 만들고, 학습시키고, 배포할 수 있도록 도와주는 서비스입니다. 이 서비스를 사용하면 복잡한 작업을 쉽게 할 수 있고, 대규모 데이터를 처리하면서도 필요한 컴퓨팅 자원을 쉽게 확장할 수 있습니다
• Compute : 컴퓨터가 복잡한 계산이 필요할 때, Azure에서는 컴퓨터 자원을 빌려서 더 빠르고 쉽게 사용할 수 있다. 예를 들어, 클라우드에서 아주 강력한 컴퓨터를 빌려서 머신러닝 모델을 학습시키는 것으로 이해하면 쉽다.
• Data Storage : 머신러닝을 하려면 많은 데이터를 사용해서 모델을 학습시켜야하므로 데이터를 안전하게 저장하고 필요할 때 쉽게 꺼내 사용할 수 있다.
• ML Workflow : 모델을 만드는 과정 전체를 자동화해주는 시스템으로 모델 학습부터 배포까지 모든 과정을 자동으로 쉽게 처리해준다.
• Model registration / management : 머신러닝 모델을 학습한 후 학습한 데이터가 어떻게 변했는지, 모델이 어떤 데이터를 사용했는지 등을 추적할 수 있게 해주는 기능
• Metrics / monitoring : 평가지표(metric) 및 데이터세트 모니터링 기능
• Model deployment : 실시간 및 일괄 처리 방식으로 모델 배포 기능

- Azure Cloud : 인터넷을 통해 서버, 저장소, 데이터베이스 등을 빌려서 사용하는 서비스
- Subscription : Azure 서비스를 사용하기 위한 계정을 만들고 구독을 통해 비용을 지불
- Resource Group : 클라우드 서비스들을 한곳에 모아서 관리할 수 있는 폴더 같은 개념으로 여러 자원을 쉽게 관리
- Workspace : Azure에서 머신러닝 프로젝트를 진행하는 공간으로 데이터를 저장, 모델 개발, 학습, 배포 등 작업 공간
Machine Learning Studio

Azure 서비스에서 머신러닝을 수행하기 위한 웹 포털. 머신러닝 모델을 학습, 테스트, 평가 및 배포할 수 있는 도구 제공
다양한 방식의 머신러닝 작업 실행할 수 있다.
- Notebooks : 프로그램 코드를 직접 작성하여 머신러닝 모델 개발
- 자동화된 ML (Automated ML) : 코딩을 하지 않고 자동으로 모델을 만들어주는 자동화 기능
- 디자이너 (Designer) : 드래그 앤 드롭으로 코딩없이 도구를 드래그하여 쉽게 모델을 만들 수 있는 도구
◆ 주제 : 날씨 데이터를 활용한 로켓 발사 예측 모델 구현
머신러닝 리소스 만들기
stable diffusion 실습 때 만들었던 리소스 그대로 사용할 예정
데이터셋 등록






Compute Instances 생성
머신러닝을 진행하기 전 컴퓨트 대상을 설정해야하는데 여기서 컴퓨트 대상이란 머신러닝을 실행할 수 있는 컴퓨팅 자원을 말한다.

각 컴퓨팅 대상은 여러 종류가 있는데 이는
- Compute Instances : 하나의 가상머신을 사용하는 것으로 개인이 사용하는 환경. 개인이 사용하며 간단한 작업의 경우 사용
- Compute Clusters : 여러 개의 가상머신을 모아서 한 번에 같이 작업을 처리하는 기능. 대규모 데이터를 처리하거나, 복잡한 머신러닝 모델을 학습시켜야 할 때 유용
- Kubernetes Clusters : 모델을 배포하고 유지보수할 때 주로 사용. 배포된 모델을 여러 사람들이 동시에 사용할 수 있도록 하고 안정적으로 실행될 수 있도록 관리하는 역할
- Attached Computes : 기존에 사용하던 컴퓨터 자원을 Azure 머신러닝 스튜디오에서 사용할 수 있도록 연결해서 사용하는 방식

딥러닝같이 무거운 모델을 학습하지 않고 가벼운 머신러닝을 진행할 예정이라 가상머신 유형을 CPU로 설정
가상머신 크기도 Standard_D2_v3로 코어 2개짜리인 가장 작은 크기로 설정해준다.

조금만 기다리면 컴퓨팅 인스턴스 실행 중 표시가 뜬다.
이제 머신러닝을 진행해주면 된다.
파이프라인 생성


데이터셋 준비

데이터 이해


데이터 아웃풋 창의 프로파일 탭을 클릭 각 컬럼 데이터의 현황(데이터 분포, 평균 등 통계 정보 및 누락값 여부 등) 확인 가능하다.
전체 컬럼 수는 26개 행은 300개로 그렇게 크지 않은 데이터임을 확인한다.
누락값을 확인했을 때 누락값이 200~300개인 경우를 여러개 확인할 수 있다. 해당 컬럼은 추후에 삭제할 것을 염두에 둔다.
또한 의미 없다고 생각이 드는 데이터를 확인한 후 추후에 컬럼 삭제할 것을 염두에 둔다.
특성(feature) 선택



Hist Ave Max Wind Speed, Hist Ave Visibility, Hist Ave Sea Level Pressure, Notes : Null값이 297개, 300개로 제거
누락값 제거

- 유인 (Crewed) / 무인 (Uncrewed) 여부 : 누락값 > Uncrewed
- 발사 여부 : 누락값 > false
- 풍향 : 누락값 > Unknown

기상조건 ( 맑음 Fair / 흐림 Cloudy / 번개 T-storm 등 12개 ) : 누락값 > 맑음(fair)
그 외의 누락 : 누락값 > 0






clean missing data 모듈을 이용해서 결측값을 어떤 값으로 대체할지 처리
메타데이터 변경
문자열 데이터 형식을 범주형 데이터로 변경 후, 순서가 없는 범주형 데이터의 경우 indicator value로 변환
컬럼의 데이터를 String 형식에서 Category(범주) 형식으로 변환한 후 Category(범주) 형식을 Convert to Indicator Values를 통해 원핫 인코딩
String > Category > 원-핫인코딩

Edit Metadata

Convert to Indicator Values

2개 이상의 범주형 컬럼을 데이터 타입을 변경한 후 원-핫 인코딩을 통해 순서가 반영되지 않도록 해준다.
원-핫 인코딩을 진행한 후 해당 컬럼으로 대체해준다.
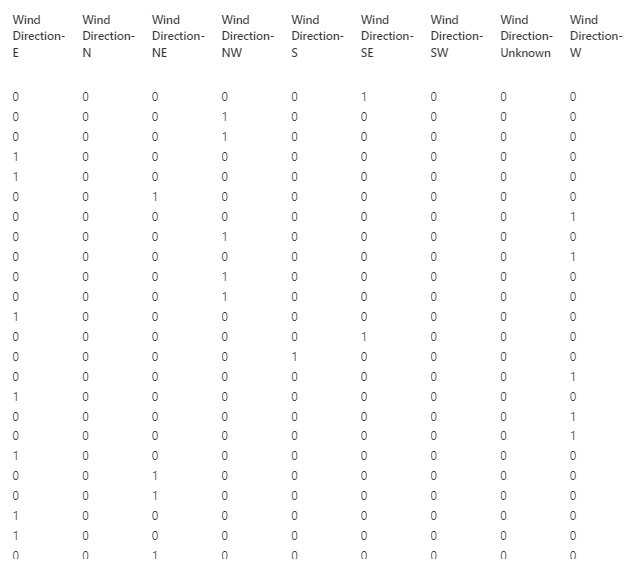
원핫 인코딩의 경우 예를 들어 1,2,3,4 로 범주화 되어 있는 컬럼의 경우 순서가 반영된다.
1보다는 2가 크고 2보다는 3이 크고..
이러한 순서성을 반영하지 않게하려면 원핫 인코딩을 통해 순서성을 없애준다.
현재까지 진행 상황을 저장 후 파이프라인 작업 실행



데이터 준비
학습데이터와 테스트데이터로 분리해준다.

▶ Split Rows : 행 단위로 분리
▶ Fraction of rows in the first output dataset : 첫번째 데이터셋(train data)의 비율을 0.7로 설정
▶ Randomized split : 데이터를 무작위 섞어 split
▶ Radom seed : True로 시드 고정 (False일 경우 실행할 때마다 데이터 분할 결과가 달라짐)
▶ Stratified split : 층화 샘플링 옵션으로 데이터 분할 시 특정 범주의 분포를 동일하게 유지(특정 범주로 편향된 데이터 불균형이 있을 경우 사용)
모델링
4가지 two-class 분류모델을 각각 학습시켜 모델을 비교해 볼 예정이다.
하이퍼파라미터는 ParameterRange로 설정해서 여러가지 하이퍼파라미터를 조합하여 모델을 학습하고자 한다.(여러 하이퍼파라미터 중 최고의 성능을 보여주는 하이퍼파라미터 조합 채택)






모델 테스트
앞에 split data에서 분리해둔 30%의 테스트 데이터를 가지고 와서 모델 테스트를 진행해준다.
모델에 테스트 데이터를 넣어 예측하고자 했던 목표변수의 분류 값을 예측(발사 가능 여부)하고 예측값에 대한 확률값을 도출해내는 과정이다.
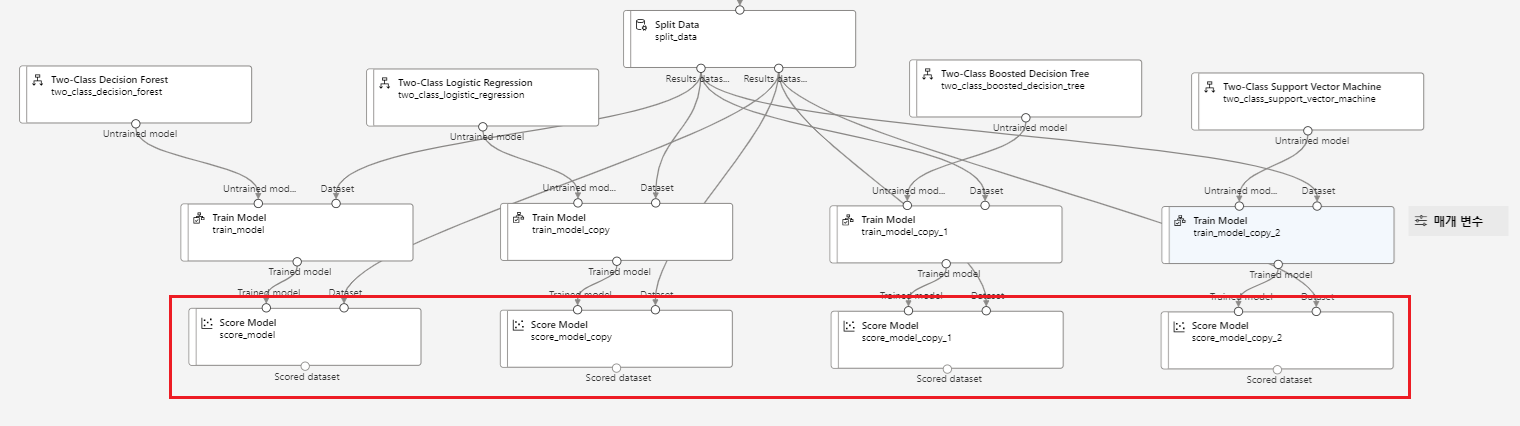
모델 평가
원본 테스트 데이터에 있던 실제 데이터 값(실제값)과 모델을 통해 예측했던 예측값을 비교하여 평가지표를 활용하여 모델을 평가한다.




마지막 모델의 경우 모든 행을 다 정확하게 예측했으므로 가장 성능이 좋은 모델임을 알 수 있다.
'Azure 실습 > Azure machine learning' 카테고리의 다른 글
| Python ML 실습 [와인 분류 - 분류 모델] (0) | 2024.10.17 |
|---|---|
| Python ML 실습 [자전거 대여 수요 예측 - 회귀 모델] (0) | 2024.10.16 |
| Azure ML Designer 실습 [군집 모델] (0) | 2024.10.11 |
| Azure ML Designer 실습 2 [자전거 대여 수요 예측 - 회귀 모델] (0) | 2024.10.10 |



