
유진의 코딩스토리
Azure Custom Vision 실습 [객체 감지 AI 모델] 본문
Custom Vision 개체 감지 AI 모델
Azure의 Custom Vision 서비스를 활용해서 특정 개체를 감지하는 애플리케이션을 만들어보자.
1단계 : 데이터 가져오기
다양한 변형을 찾을 수 있도록 가능한 한 많은 이미지를 수집한다.
2단계 : 특징 추출
인간의 뇌는 각 이미지에서 특징을 추출하려고 한다. 특징에는 색 조합, 날카로운 가장자리, 원형 패턴, 표면의 질감, 크기 등이 있다. 인간의 뇌는 자연스럽게 이러한 특징들을 고려하여 분류를 진행한다.
3단계 : 관계 찾기
인간은 사진에 표시된 개체의 특징과 종류 간의 관계를 찾으려고 한다. 뇌는 각 개체 종류의 특성 및 특징을 분리하거나 대조하려고 한다.
4단계 : 종류 분류
새로운 이미지가 제공되면 뇌는 해당 특성을 추출하고 이미 만들어 놓은 연관 관계를 사용하여 개체 종류를 결정한다.
Custom Vision으로 오버더문에 나오는 번지 캐릭터를 찾는 개체 감지 AI 모델을 만들어보자.
AI 학습에 필요한 이미지 선택
1. 학습 이미지셋
• 오버 더 문영화의 토끼 번지 이미지를 사용
2. 테스트 이미지셋
• AI 테스트에 사용하려는 예측 이미지를 만들어야 한다.
• 예측 이미지를 Custom Vision 서비스 학습에 사용할 수 없다.
3.유의해야 할 기타 사항
• .jpg, .png, .bmp 또는 .gif 형식 중 하나여야 한다.
• 크기가 6MB 이하여야 한다.
• 가장 짧은 가장자리가 256픽셀 이상이어야 한다.
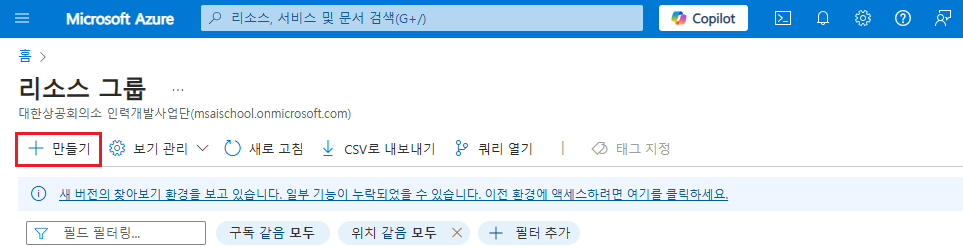
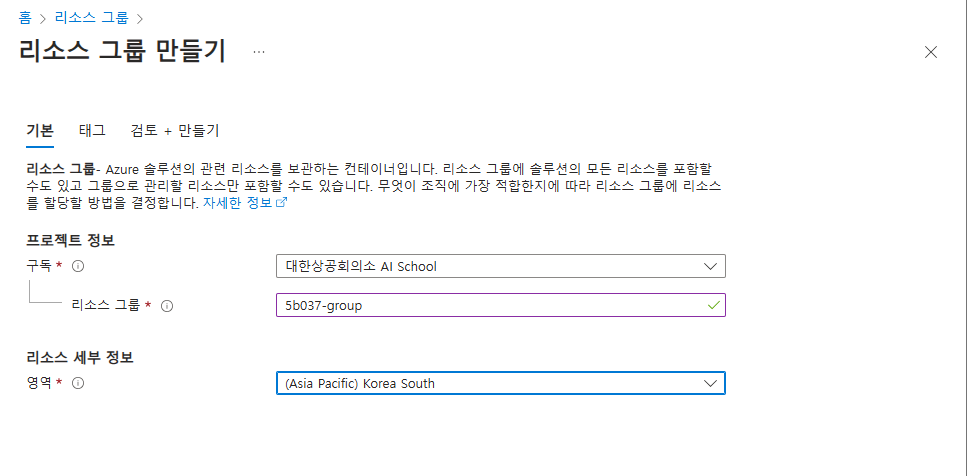
리소스 그룹 만들기
azure resource group은 여러 Azure 리소스를 논리적으로 묶어 관리하는 컨테이너 역할
특정 프로젝트나 애플리케이션과 관련된 리소스를 그룹화하여 관리할 수 있다.
Custom Vision 리소스 만들기
Custom Vision 리소스를 사용하면 코드를 한 줄도 작성하지 않고도 이미지를 업로드하고, 이미지 분류 모델을 학습하고, 모델을 테스트할 수 있다.
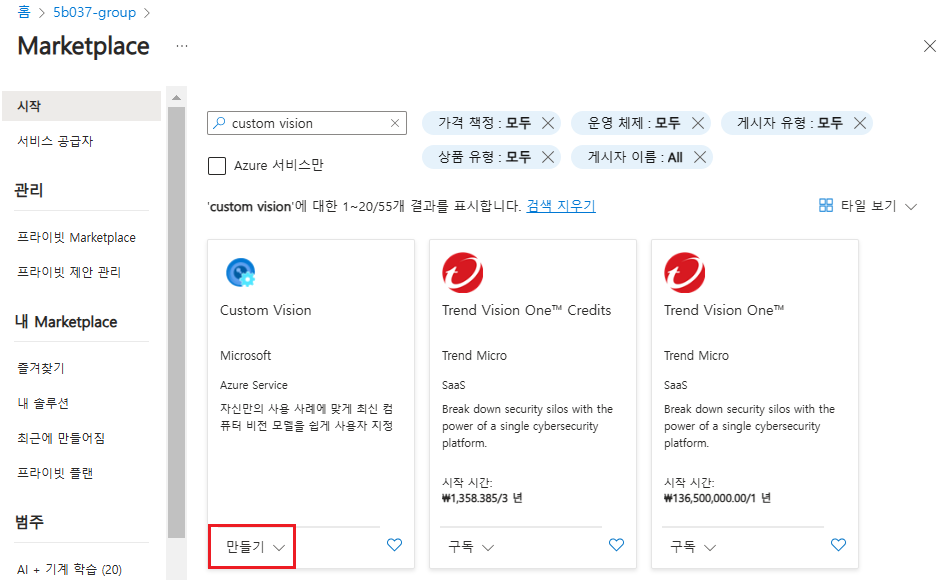
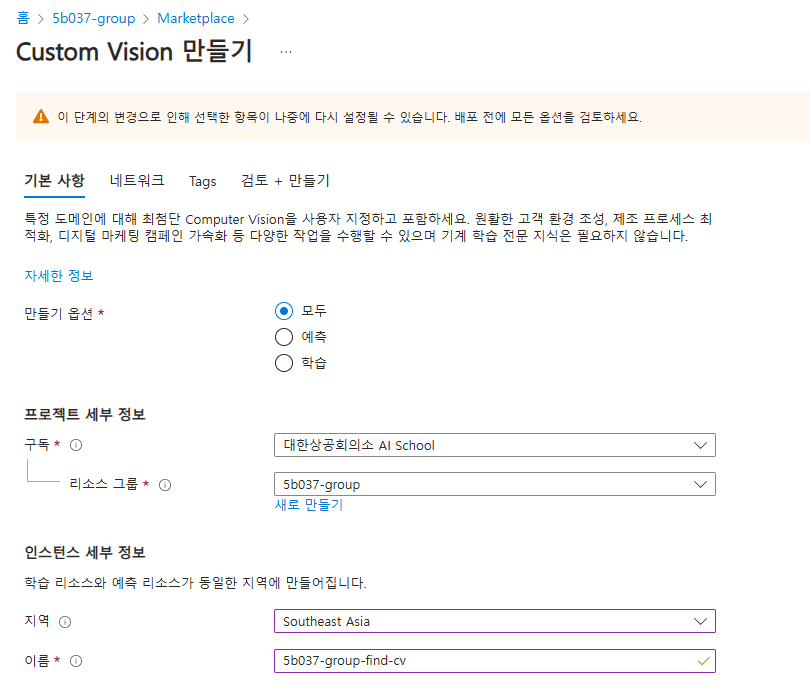
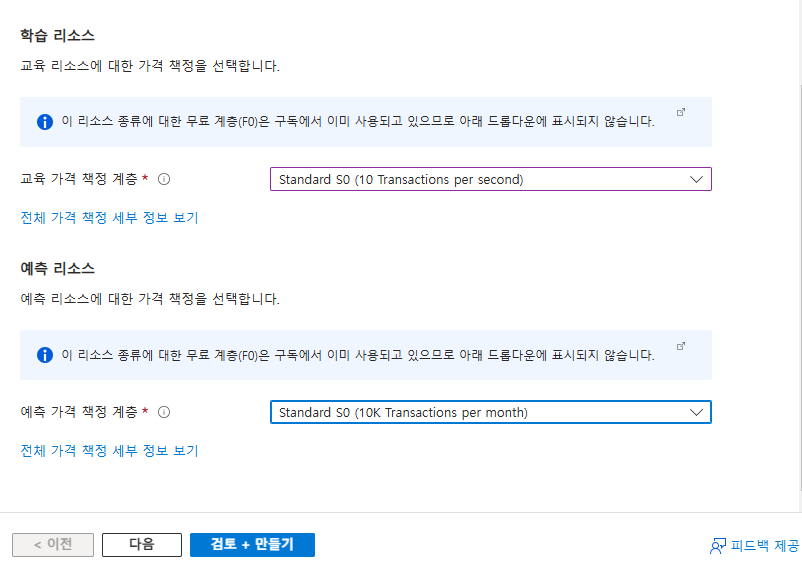
구독 계정과 리소스 이름 설정 > 학습과 예측 리소스에서 학습과 예측 위치에 가까운 지역을 선택.
교육 가격 책정 계증에서 Standard 계층을 선택한다.(free는 너무 느림..)
만들기 누르고 배포 완료까지 되면 완성.
프로젝트 만들기
이미지 업로드
이미지 태그
업로드된 이미지에 태그를 지정한다.
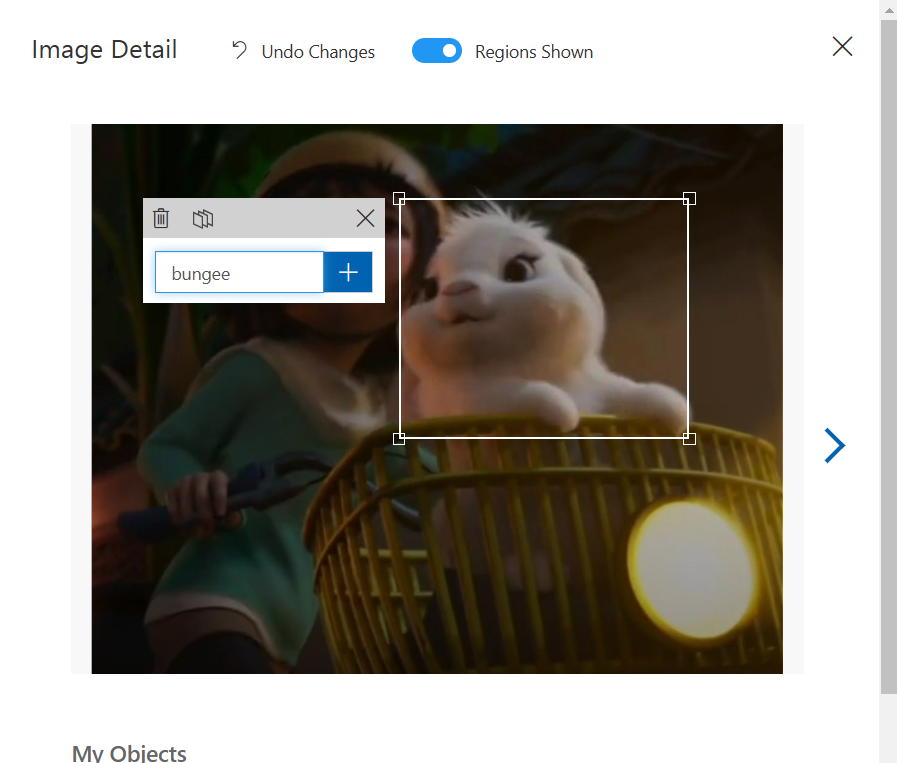
먼저 한 이미지를 선택하면 창이 펼쳐지고 내부에 이미지가 표시된다.
이미지를 선택하면 개체 주위에 상자가 표시되고 개체에 정확하게 맞도록 상자를 조정한다.
모든 이미지에 태그를 지정하고 나면 프로젝트의 태그 지정영역에 모두 표시된다.
모델 학습
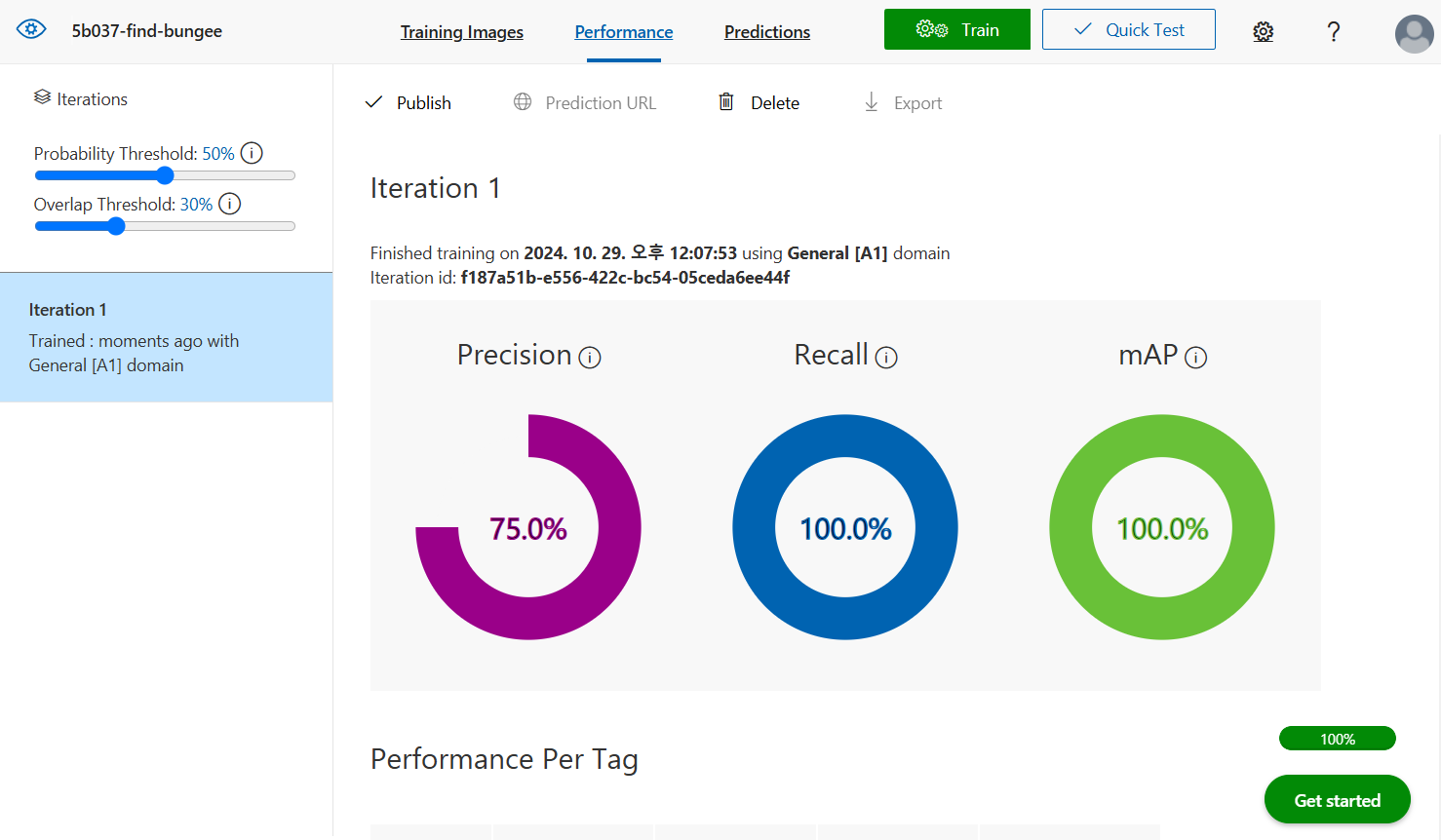
모델 학습 결과

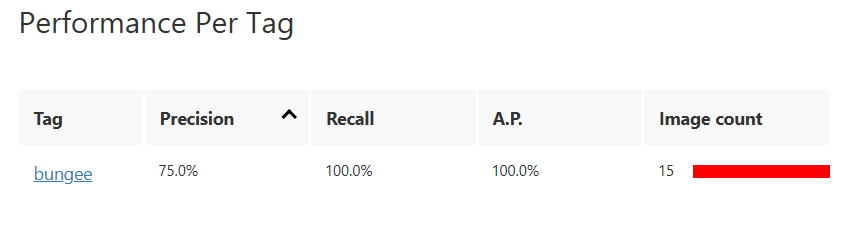
정밀도(Precision) : Positive 예측값 중 진짜 Positive인 비율 ← 가짜 Positive가 있어서는 안되는 경우 사용
재현율(Recall) : 진짜 Positive 중 예측이 맞춘 비율 ← 진짜 Positive를 못 맞추면 안되는 경우 사용
모델 테스트

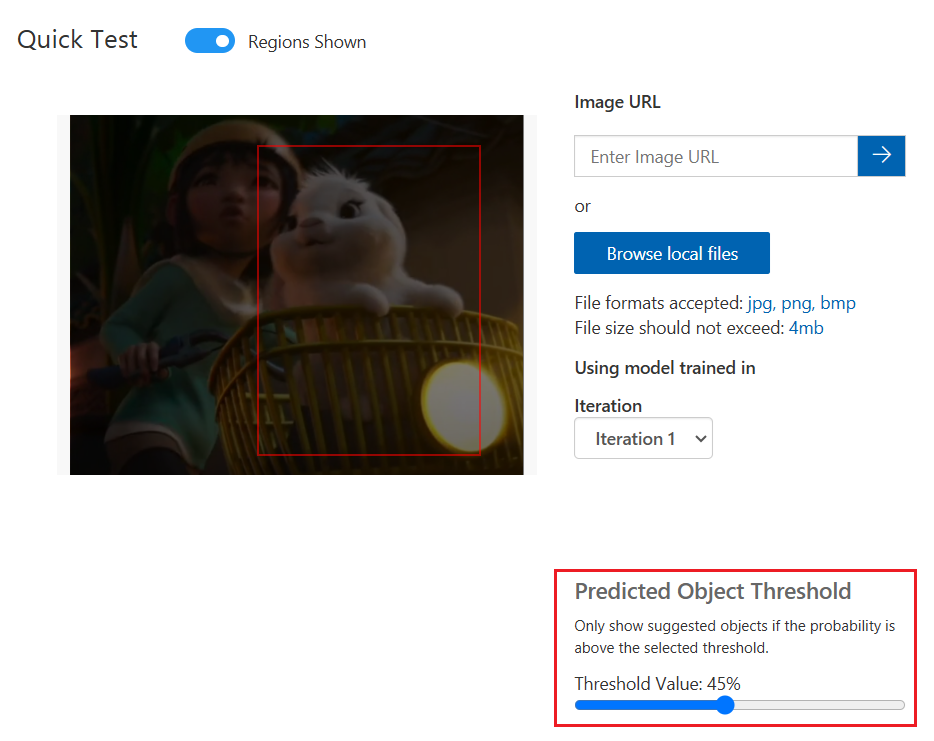
Predicted Object Threshold는 확률 임계값으로 예측이 정확한지 확인하기 위해 학습 시 필요한 최소한의 신뢰도 범위 임계값이다. 확률 임계값이 50%이면 사진이 토끼 번지라고 50%이상 확신하는 확률만 취급한다.
사진에서 개체가 있다고 생각하는 위치 주위에 여러 다른 경계 상자도 같이 보여준다. 임계값이 30%이면 AI에서 개체를 포함한다고 예측하는 경계 상자의 30% 이상이 올바른 개체를 탐지하는 경계 상자이다.
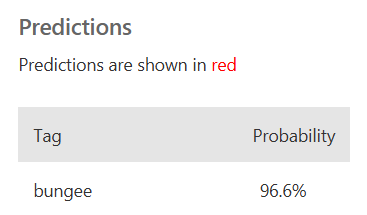
Predictions는 해당 상자 속 번지가 있다고 생각되는 확률값으로 해당 테스트 사진은 번지가 있을 확률이 96.6%이다.
번지 태그 외에 추가로 영화에서 번지가 아닌 이미지에 토끼 번지 아님태그를 만들어 학습 시키면 예측 확률이 좋아질 수 있다.
Custom vision을 외부에서 활용하기
Azure의 Custom Vision은 Azure Portal과는 독립된 별도의 사이트에서 제공되는 서비스로 사용자가 만든 컴퓨터 비전 모델을 바로 확인할 수 있는 UI를 제공한다.
REST API 호출을 통해서 사용자가 만든 Custom Vision 모델을 외부 프로그램에서 활용할 수 있다.
이미지 분류 서비스와 연동하기
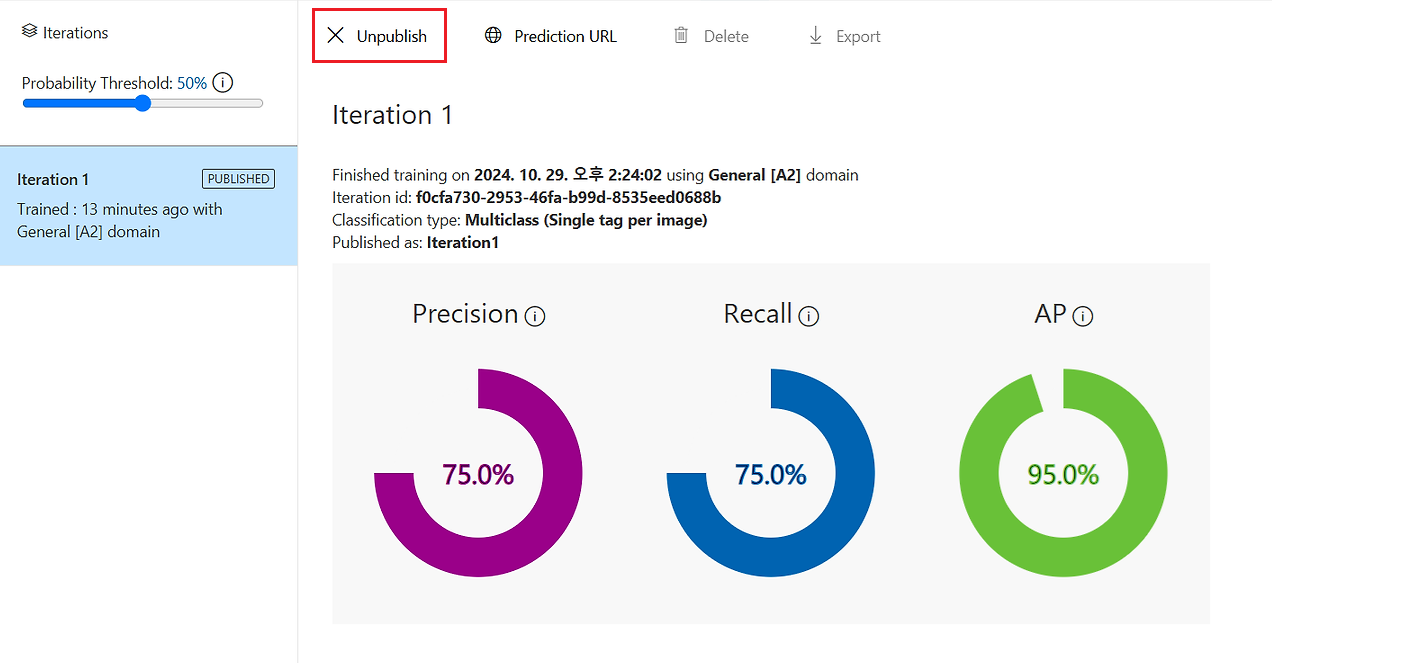
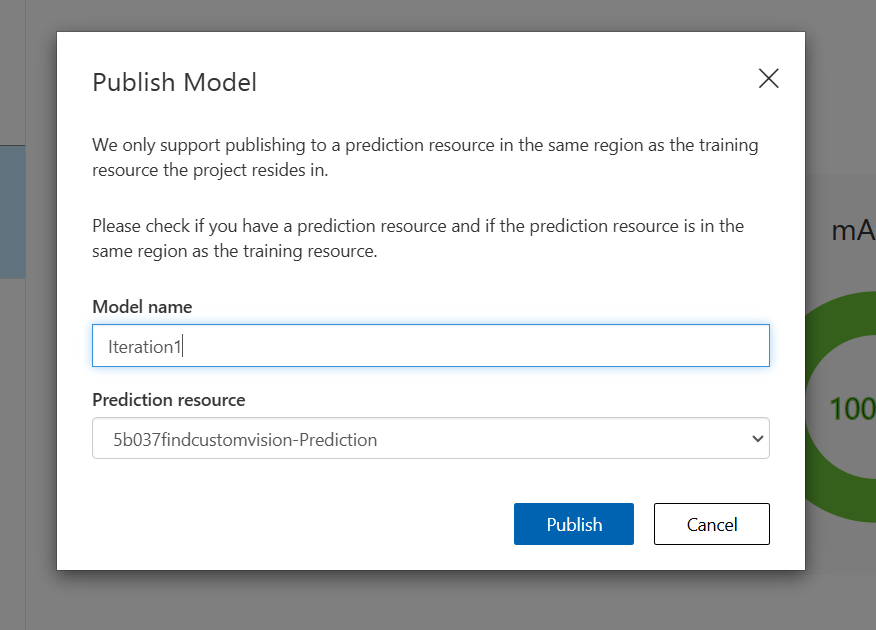
방금 만든 모델을 Publish하여 외부에서 사용할 수 있도록 한다.
Publish Model에서 내가 만든 예측 리소스를 선택
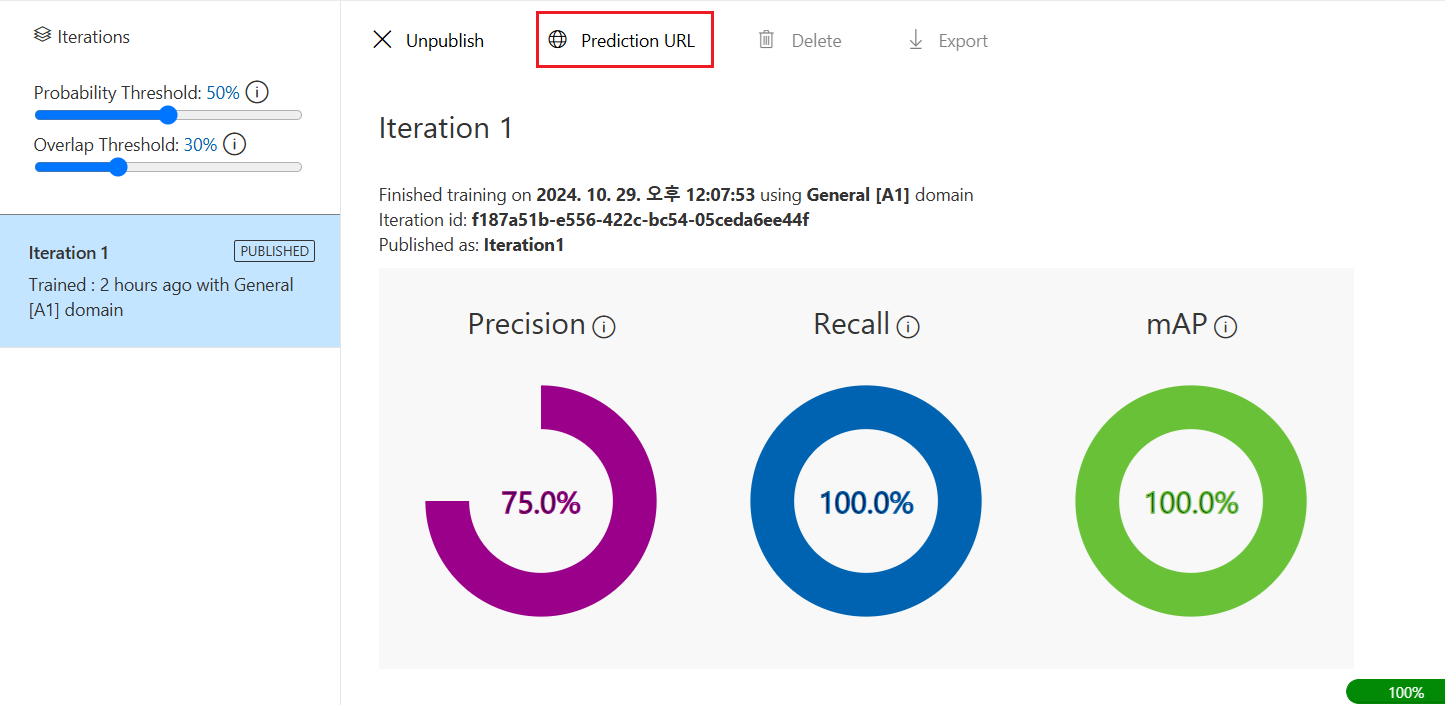
Publish가 완료되면 아래와 같이 ‘PUBLISHED’라는 표시가 나오고, Prediction URL 버튼이 활성화된다.
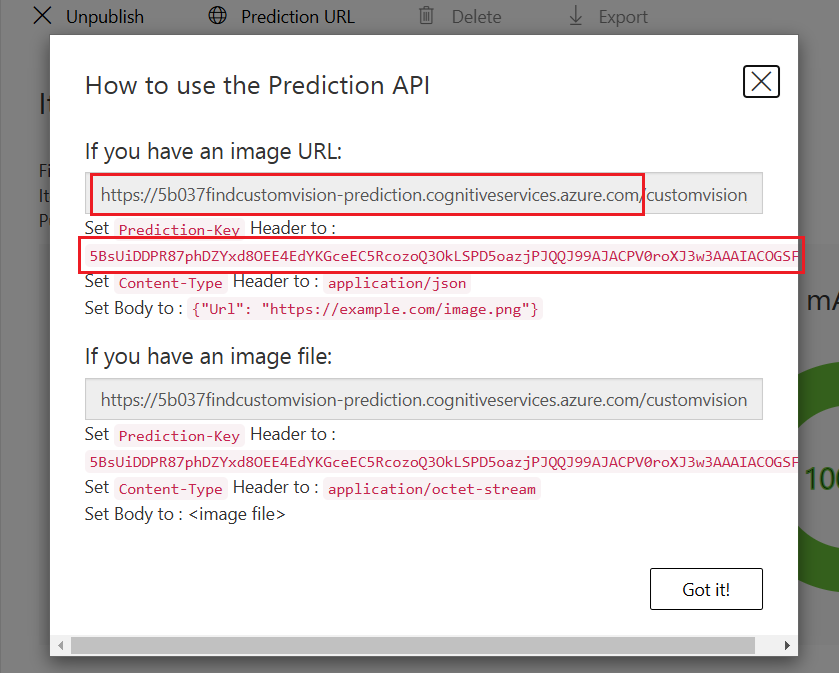
Prediction URL을 눌러서 나오는 빨간 네모 박스 속 내용을 뒤에서 사용하므로 복사!!
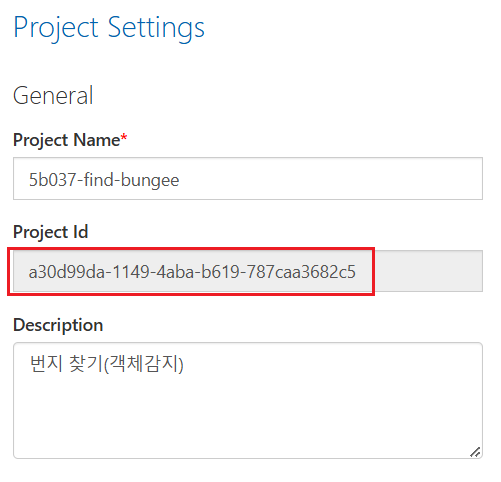
톱니바퀴 모양을 클릭하면 Project Id가 보이는데 뒤에서 사용하므로 복사!!
# Azure의 Custom Vision 라이브러리를 추가. 예측을 위하여 prediction을 포함
from azure.cognitiveservices.vision.customvision.prediction import CustomVisionPredictionClient
# OpenAPI스펙에 맞춰서 Authentication을 처리할 수 있도록 해주는 코드
from msrest.authentication import ApiKeyCredentials
# Matplotlib의 pyplot을 포함하여 예측 결과를 그리기
from matplotlib import pyplot as plt
# Python Image 라이브러리로 이미지 그리기
from PIL import Image, ImageDraw, ImageFont
# Python Numpy (수학 및 과학 연산 패키지) 포함
import numpy as np
# 파일 처리 작업을 위해 os라이브러리 포함
import os
# 사용자가 만든 AI 모델의 예측 기능을 사용하기 위한 endpoint 지정
prediction_endpoint = "https://5b037findcustomvision-prediction.cognitiveservices.azure.com"
# KEY 값 지정
prediction_key = "5BsUiDDPR87phDZYxd8OEE4EdYKGceEC5RcozoQ3OkLSPD5oazjPJQQJ99AJACPV0roXJ3w3AAAIACOGSFBw"
# 프로젝트 ID 지정
project_id = "9838c357-d3fb-4084-99c2-1592155a2017"
# 모델명 지정
model_name = "Iteration1"
# 앞에서 지정한 API KEY를 써서 커스텀 비전 모델을 사용할 클라이언트를 인증
credentials = ApiKeyCredentials(in_headers={"Prediction-key": prediction_key})
# endpoint를 써서 클라이언트 등록
predictor = CustomVisionPredictionClient(endpoint=prediction_endpoint, credentials=credentials)
# 테스트 이미지를 Codespace workspace에 추가한 후 image_file 변수로 지정
image_file = "/workspaces/PyTorch_excersize/data/test-1.png"
# 이미지 파일 등록되었음을 출력
print('Detecting objects in ', image_file)
# Python Imaging Library의 image open함수를 써서 테스트 이미지 파일 오픈
image=Image.open(image_file)
# Numpy에서 이미지의 shape을 높이, 폭, 채널 읽기
h, w, ch = np.array(image).shape
# 테스트 이미지를 열고 모델에 적용해서 결과를 저장
with open(image_file, mode="rb") as image_data:
results = predictor.detect_image(project_id, model_name, image_data)
# 예측한 결과를 모두 출력 (텍스트로 표시됨)
for prediction in results. predictions:
print("\t" + prediction.tag_name + ": {0:.2f}% bbox.left = {1:.2f}, bbox.top = {2:.2f}, bbox.width = {3:.2f}, bbox.height = {4:.2f}".format(prediction.probability * 100, prediction.bounding_box.left, prediction.bounding_box.top, prediction.bounding_box.width, prediction.bounding_box.height))
# 그래프 크기 지정하고 축 비활성화
fig = plt.figure(figsize=(8,8))
plt.axis('off')
# 테스트 이미지를 그리기
# 개체 인식 박스를 magenta로 지정
draw = ImageDraw.Draw(image)
lineWidth = int(w/100)
color = 'magenta'
# 개체 인식된 모든 결과에 대해서
for prediction in results. predictions:
# 확률이 50%이 이상인 경우 bounding box 값을 읽음
if (prediction.probability*100) > 50:
left = prediction.bounding_box.left * w
top = prediction.bounding_box.top * h
width = prediction.bounding_box.width * w
height = prediction.bounding_box.height * h
# bounding box 값을 magenta색으로 표시
points = ((left,top), (left+width,top), (left+width,top+height), (left,top+height),(left,top))
draw.line(points, fill=color, width=lineWidth)
plt.annotate(prediction.tag_name + ' {0:.2f}%'.format(prediction.probability * 100), (left, top), color=color)
# bounding box 표시된 이미지를 output.jpg로 저장
plt.imshow(image)
outputfile = 'output.jpg'
fig. savefig(outputfile)
print('Results saved in', outputfile)
'Azure 실습 > Azure Custom Vision' 카테고리의 다른 글
| Azure Custom vision 실습 [이미지 분류 AI 모델] (0) | 2024.10.29 |
|---|
